Automated real-time detection of closed-loop communication in spoken dialogue
Table of Contents
- 1 Introduction
- 2 Task 1: Wearable audio streaming device (WASD)
- 3 Task 2: Closed loop communication (CLC) detector
- 4 Team
- 5 Acknowledgments
- References
1 Introduction
Good teamwork processes enable teams to perform beyond the sum of their parts (Roberts et al., 2021). Closed loop communication (CLC) has been proposed in the team science literature as one of the coordinating mechanisms for effective teamwork (Salas et al., 2005), and has been demonstrated to improve team outcomes in a variety of domains. Currently, CLC in spoken dialogue is identified via retrospective analyses involving manual transcription and annotation. However, given the potentially catastrophic consequences of poor team communication – especially in complex, fast-paced, and high stakes environments such as operating theaters (Flin & Maran, 2004) – we argue that there is an urgent need for AI technologies that can detect and repair breakdowns in CLC as they happen. To address this need, we propose to develop an AI system for detecting the presence or absence of CLC in spoken dialogue within teams of humans collaborating on shared tasks.
Currently, most dialogue systems that understand and respond to human speech in real time (e.g., Siri, Alexa, Google Assistant) are limited to conversing with a single human at a time. On the other hand, there are numerous analyses of multi-participant spoken dialogue in the academic literature – however, these analyses are primarily performed offline rather than in real-time.
The dialogue system we are building in the ToMCAT project addresses both of these limitations. However, since the system was developed in the context of experiments involving teams of remote participants performing collaborative tasks in a Minecraft-based environment, audio is currently streamed via the web browser, with an interface specialized for these particular experiments. In order to test our dialogue system in more general contexts, especially ones that involve more ambulatory participants, we need a new ‘frontend’.
2 Task 1: Wearable audio streaming device (WASD)
From our work on analyzing spoken dialogue datasets, we have learned that source separation is a significant challenge when it comes to analyzing spoken dialogue between physically collocated teams. In other words, if a multi-participant dialogue is recorded using a single microphone, or even an array of non-individualized microphones, it is difficult for a computer to determine who is speaking at any given moment. With recent advances in wearable technology and single-board computers (SBCs), we are in a position to bypass this issue entirely. Specifically, we will develop a wearable audio streaming device (WASD) that captures an individual’s audio and streams it wirelessly to a server for further processing, e.g., by the ToMCAT dialogue system. Each participant in an experiment to study spoken team dialogue will be equipped with a WASD, which consists of a lavalier microphone, a credit-card sized SBC and a battery pack (see Figure 1).
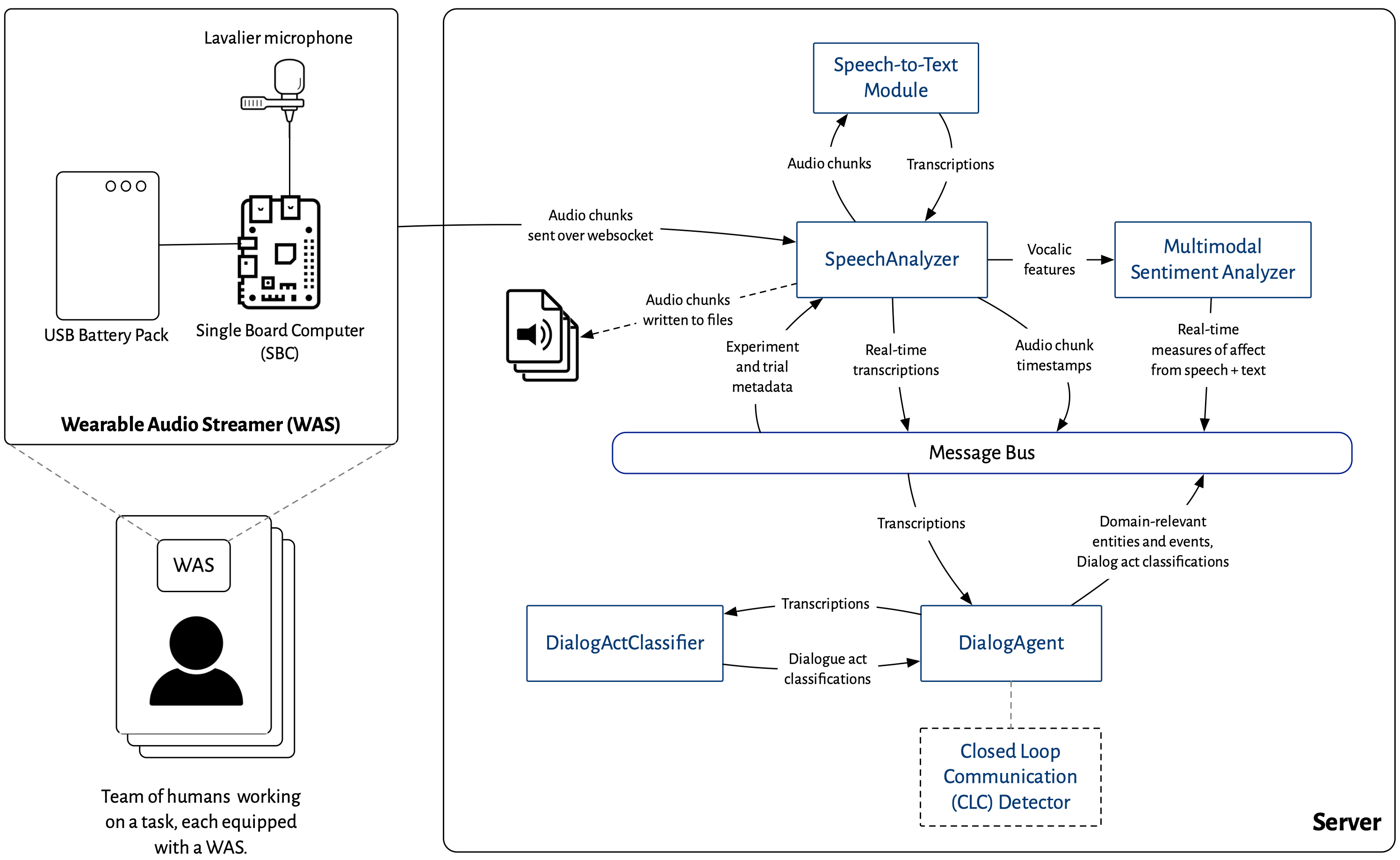
3 Task 2: Closed loop communication (CLC) detector
The existing ToMCAT dialogue system is currently able to analyze spoken conversations in real time to extract entities and events of interest with a powerful rule-based framework (Valenzuela-Escárcega et al., 2016), classify dialogue acts, and detect sentiment. We propose to extend this system to detect closed loop communication as well. We will start by implementing a set of rules in the module, and then explore whether machine learning techniques improve its performance.
4 Team
The team for this consists of the following people:
- Graduate Research Assistants
- Yuwei Wang
- Chen Chen
- Gauri Yadav
- Undergraduate Research Assistants
- Minh Duong
- Aditya Banerjee
- Aditya Jadhav
- Research Programmers
- Vincent Raymond
5 Acknowledgments
This research is generously supported by the University of Arizona SensorLab via two intramural seed grants.
We are also collaborating with the UArizona Holodeck for this project.